
One kind of recurrent neural network (RNN) that is intended to learn and anticipate sequential input is called long short-term memory (LSTM). Because of their ability to process and store data across several time steps, LSTMs are employed in a wide range of applications, such as:
- Speech recognition
- Speech synthesis
- Language modeling and translation
- Handwriting recognition
- Audio and video data analysis
- Protein secondary structure prediction
Because LSTMs employ gates to selectively retain or discard input, they are able to learn long-term dependencies. An input gate, an output gate, and a forget gate are among these gates:
- Input gate: Decides which information to store in the memory cell
- Output gate: Decides which information to use for the LSTM’s output
- Forget gate: Decides which information to discard from the memory cell
LSTMs are able to overcome the vanishing gradient problem that traditional RNNs encounter. This problem occurs when the neural network output decays or explodes as it cycles through feedback loops
A recurrent neural network (RNN) is a type of artificial neural network in which nodes are connected in a directed graph that follows a temporal sequence. This enables it to behave in a temporally dynamic manner.
A feedforward neural network is a type of artificial neural network in which nodes’ connections do not form a loop. As a result, it differs from its offspring, recurrent neural networks.
Deep learning (also known as deep structured learning) is a type of machine learning technology that uses artificial neural networks to learn representations. There are three types of learning: supervised, semi-supervised, and unsupervised.
Predicting the future was once a thing of speculation and mystery. Thanks to human advancements, it has become a task only limited by the amount and depth of data.
This work of foresight is becoming more accessible since we live in a civilization that generates data at an exponential rate. Predicting the future used to be a source of mystery and debate. It has become a task limited only by the number and depth of data thanks to human developments. The term LSTM will inevitably crop up as you explore more into data-driven predictions. It is an abbreviation that stands for Long Short Term Memory, like many other tech concepts. Simply said, it’s a Neural Network — a machine learning system that mimics human learning patterns — that can “remember” past facts and results and apply them to arrive at a more accurate conclusion.
LSTM has potential in any sequential processing activity where we assume a hierarchical breakdown exists but don’t know what it is. LSTM is a type of Recurrent Neural Network in Deep Learning that has been specifically developed for the use of handling sequential prediction problems.
For example:
- Weather Forecasting
- Stock Market Prediction
- Product Recommendation
- Text/Image/Handwriting Generation
- Text Translation
Neural Networks, contain neurons to perform computation, however, for LSTM, they are often referred to as memory cells or simply cells. These cells contain weights and gates; the gates being the distinguishing feature of LSTM models. There are 3 gates inside of every cell. The input gate, the forget gate, and the output gate.
Important Variables

— LSTM Gates —
The Cell State:
")
The cell state is sort of like a conveyor belt that moves the data along through the cell. While it is not technically a gate, it is crucial for carrying data through each individual cell as well as to other cells. The data flowing through it is altered and updated according to the results from the forget and input gates and passed to the next cell.
The Forget Gate:
")
This gate removes unneeded information before merging with the cell state. Just as humans choose to not consider certain events or information that is not related or necessary for making a decision. It takes in 2 inputs, new information (x_t) and the previous cell output (h_t-1). It runs these inputs through a sigmoid gate to filter out unneeded data and then merges it with the cell state via multiplication.
The Input Gate:
")
This gate adds information to the cell state. The human equivalent is considering newly presented information on top of the information you already have. Similar to the forget gate, it employs a sigmoid gate to determine what amount of information needs to be kept. It uses the tanh function to create a vector of the information to be added. It then multiplies the results from the sigmoid gate and tanh functions and adds useful information to the cell state using addition. At this point, all information has been set up: starting information, new information, and the dropping of unneeded information. It’s all gathered and compiled and a decision is ready to be made.
The Output Gate:

The last gate selects useful information based on the cell state, the previous cell output, and new data. It does this by taking the cell state, after the input and forget gates have merged, and runs it through a tanh function to create a vector. It then takes the new data and previous cell output and runs them through a sigmoid function to find what values need to be outputted. The results of those 2 operations are then multiplied and returned as the output of this cell.
")

This entire process of the data moving through the cells is happening in 1 cell. But in an actual model, there can be any amount of cells, per layer, for however many layers are added before a final conclusion is reached. Then that entire model is run again for however many epochs (iterations) are needed to get closer to a more accurate answer. The better the accuracy; the better the prediction.
LSTM models are able to look back at previous data and decisions and make decisions from that. But they are also to use that same process to make educated guesses/predictions about what can happen. Thus this model is best when fed sequential data. It will find trends and use those trends to predict future trends and results. But perhaps not with the same level of accuracy. Let alone taking in millions of data points as input.
Stock market forecasting and prediction we’ll look at one stock, and one firm, and see whether we can anticipate and forecast using stacked LSTM. we are going to use stacked LSTM long short-term memory and we have explained to you step by step and TensorFlow greater than 2.0 okay so I’ve used this library I’ve used LSTM
")
First, we’ll collect stock data; in this case, I’m using SBIN data, which is State Bank of India stock prices from 2016 to September 24th. I’ll try to take that data, and then we’ll pre-process it, which means we’ll divide it into train tests. Before we can do that, we’ll need to perform a bunch of pre-processing, which I’ll explain, and then we’ll develop a stack holistic model.
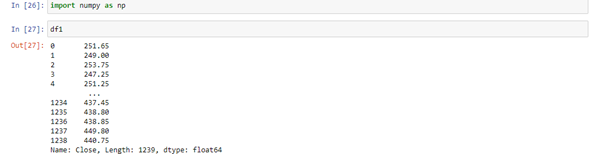
We’ll train it, then predict the test date and plot the output, and finally, we’ll predict the future 30 days because that basically means the future one month from today’s May month, so we’ll try to predict that and I’ll try to show you the output and plot it as well. So let’s get started with the first step.
We’re going to use a tremendous number of libraries where you can actually get this kind of data, so we’ve extracted the data from the NSEPY library, which contains all of the NSE data. You can collect as much data as you like.
")
You may use Matplotlib to plot as PLT. As you can see, our stock price has been moving up and down from 2016 to 2021.
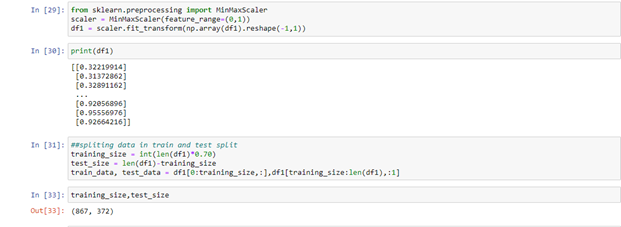
LSTM is quite sensitive to the scale of the input, and this data doesn’t have any kind of scale.
So always transform this particular value, MinMaxScaler will be transforming our values from 0 to 1 from a scale under pre-processing.
In the min max scaler feature ranges between 0 and 1, so this is the value you’ll need to give when you want to scale down between 0 and 1. Need to pre-process the data time series data, and divide the data set 70% of the initial data is in our training data to undertake data pre-processing after this division, 30% of the data will be test data. Sequence of data or time series data, the following data is always dependent on the prior data. Splitting the data set into train and test splits, so first take train size, which should be exactly the current size in this case, which is 70% of the total length of the data frame.
The training size is 867 and my test site is 372 and then the rest of the data will be stored in the test data after 867 indexing. If I show you the length of my training data, which is my train data over here, you can see that it’s 867, and similarly, if I show you the length of test data 372. The most important step completed is the Train test, we need to do data pre-processing.
With this collection of training data, predict this test data set in an LSTM model and compare it to my y_ test to determine how accurate the forecasting is. Data pre-processing is relatively simple now.
We’ve finished processing and are ready to go on to the next phase, which is to create a stack LSTM model. Before implementing any LSTM, it’s important to always reshape extremes.
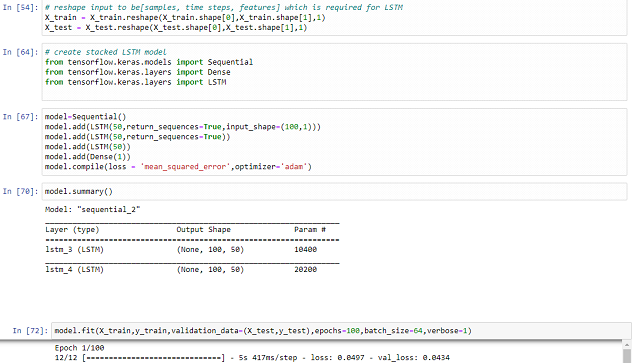
Created a method called variant data set where we actually take the data set then on a time stamp in the time stamp by default whatever values are given like hundred it will take 100-time stamp like this here, in this case, it is 3 times stamp so it will take 100 timestamp
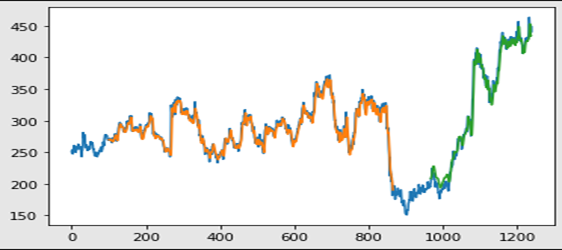
100 epochs, in this case, the test rate of predicted output that is basically green color output over here the blue color output is the complete data set for the training data set that how the prediction has gone is basically this orange and green color predicted and need to do the scalar. The next step that we have predict the output and predict the future 30-day length of the test underscore database it is for 272 records.
The prediction is that at the end this is 30-day and it will be actually smooth compared to this zigzag had this particular stock price right it is actually smooth and see that it is also going up and down if you want to really see in a proper way just start from start date now here you all the data or the stock price is predicted.
Contact us for your wealth management and more information.
Email: pramod.gamare@hotmail.com
Phone: 7559411986
Post Disclaimer
Disclaimer
1. The Alpha Wealth is a wealth advisory offering financial services viz and third-party wealth management products. The details mentioned in the respective product/ service document shall prevail in case of any inconsistency with respect to the information referring to BFL products and services on this page.
2. All other information, such as, the images, facts, statistics etc. (“information”) that are in addition to the details mentioned in the The Alpha Wealth product/ service document and which are being displayed on this page only depicts the summary of the information sourced from the public domain. The said information is neither owned by The Alpha Wealth nor it is to the exclusive knowledge of The Alpha Wealth. There may be inadvertent inaccuracies or typographical errors or delays in updating the said information. Hence, users are advised to independently exercise diligence by verifying complete information, including by consulting experts, if any. Users shall be the sole owner of the decision taken, if any, about suitability of the same.
Standard Disclaimer
Investments in the securities market are subject to market risk, read all related documents carefully before investing.
Research Disclaimer
Sub-Broking services offered by Sharekhan LTD | REG OFFICE: Badlapur, Thane 421503. Corp. Office: ---, Maharashtra 421503. SEBI Registration No.: --| BSE Cash/F&O/CDS (Member ID:--) | NSE Cash/F&O/CDS (Member ID: --) | DP registration No: --- | CDSL DP No.: --| NSDL DP No. --| AMFI Registration No.: ARN –253455.
Website: https://thegreenbackboogie.com//
Research Services are offered by The Alpha Wealth as Research Analyst under awaiting SEBI Registration No.: ---.
Details of Compliance Officer: -- | Email: --/ --- | Contact No.: -- |
This content is for educational purpose only.
Investment in the securities involves risks, investor should consult his own advisors/consultant to determine the merits and risks of investment.